AutoBench: A Holistic Platform for Automated and Reproducible Benchmarking in HPC Testbeds
DOI: https://dl.acm.org/doi/10.1145/3680256.3721332
Abstract
Benchmarking is indispensable for evaluating HPC systems and architectures, providing critical insights into their performance, efficiency, and operational characteristics. However, the increasing heterogeneity and complexity of modern HPC architectures 1 present significant challenges for benchmarking to achieve consistent and comprehensive insights.
Likewise, commercial HPC environments encounter similar challenges due to their dynamic and diverse nature. Therefore, it is crucial to have automatic benchmarking of platforms, which consider holistic configuration options across various layers including the operating system layer, the software stack layer, among others.
This paper presents AutoBench, an automated benchmarking platform designed to target benchmarking on testbed systems at HPC and Cloud data centers to address the above challenges. %and is adaptable to cloud environments. With its multi-layered, customizable configuration options, AutoBench assists benchmarking across diverse systems. In addition, AutoBench enables automation, exploration of optimal configurations in multiple layers, and reproducibility.
We demonstrate how we use this benchmarking tool in the BEAST system 2 at Leibniz Supercomputing Centre (LRZ) to provide comparisons between various architectures and their benefits. We also demonstrate that AutoBench can reproduce benchmarks with an acceptable variance of ~5%.
Sample Layered Cluster Configuration
The figure 1 shows a sample cluster configuration folder structure for beast, including the ice partition, nodes, and scheduler settings detailing shell preference, job script template, and submission command.
config/└── cluster/ ├── beast/ ├── beast.yaml ├── 1_systems └── ice.yaml ├── 2_oss └── ice.yaml ├── 3_softwares └── ice.yaml └── 4_benchmarks └── ice.yaml └── scheduler ├── config.yaml ├── slurm_job_template.txt └── flux_job_template.txtFigure 1: Hierarchical Directory Structure for the BEAST Cluster Featuring the ice Partition and Associated Scheduler Configuration Templates.
User Workflow
Figure. 2 presents the sequence of user workflow steps along with their respective commands.
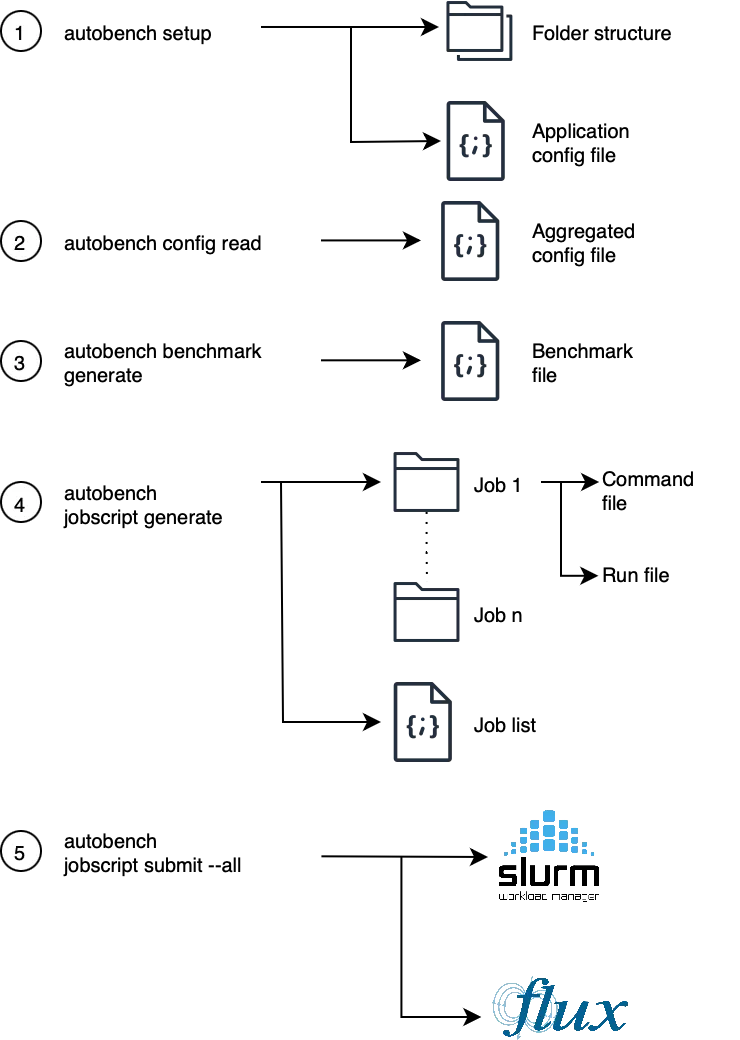
Figure 2: Displays the user workflow commands used to create job scripts and submit them to the scheduler 34
Concrete Generated Benchmark
Below is an instance of a HPL benchmark created for the ice1 node, running SUSE OS, configured at 2.4GMHz with an icelake CPU, and utilizing gcc as the compiler.
{ "BID": 0, "cluster": "beast", "partition": "ice", "system": { "target_components": "icelake_cpu" }, "os": { "os": "suse", "freqs": "2.40GHz" }, "software": { "model": "hpl_mpi", "compiler": "mpicc", "hpl_version": "2.3-gcc-13.2.0-726jfer", "model_type": "omp", "mount_path": "/home/sw/ice/spack/share/spack/modules", "teams": 1 }, "benchmark": { "benchmark": "hpl", "np": 72, "nb": 192, "configpath": "../configs/cluster/beast/4_benchmarks/hpl_ice" }}Multistage Software Stack Framework
The code below showcases the software stack configuration, deployed using a multistage software stack framework
clusters: - name: beast toolkits: - zlib partitions: - name: ice build_server: ice1 compilers: - gcc@13.2.0 - llvm@17.0.4 +flang %gcc@13.2.0 benchmarks: - osu-micro-benchmarks@7.3 - ior@3.3.0 - mdtest@1.9.3 - hpcc@1.5.0 ^netlib-lapack - hpcg@3.1 - babelstream@4.0 +stddata - stream@5.10 - lulesh@2.0.3 - caliper - hpl@2.3 ^openblasDeployment of AutoBench Infrastructure
To deploy AutoBench infrastructure on a cluster, we presume that similar nodes (e.g., with similar architectures or hardware components) are grouped into partitions, each running the same OS. The essential software stack for each partition is then built using the Spack, followed by the installation of the SLURM scheduler. Additionally, the necessary repositories are established and configured with appropriate access levels. CI runners and DCDB are configured for monitoring on frontend/login nodes, and DVFS and similar tools are deployed on compute nodes with elevated user permissions, completing the setup.
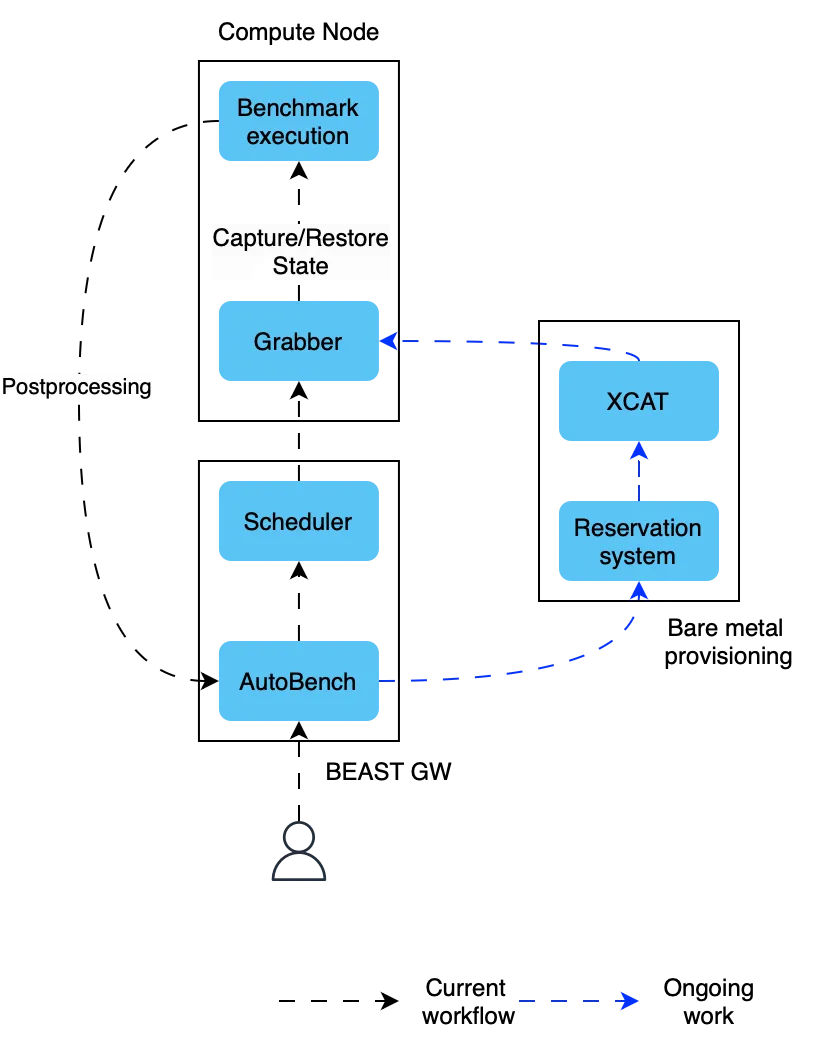
Reproducibility workflow
References
Footnotes
-
Schulz, Martin and Kranzlm”{u}ller, Dieter and Schulz, Laura Brandon and Trinitis, Carsten and Weidendorfer, Josef, On the Inevitability of Integrated HPC Systems and How they will Change HPC System Operations, Association for Computing Machinery,2021 DOI. ↩
-
Raoofy, Amir and Elis, Bengisu and Bode, Vincent and Chung, Minh Thanh and Breiter, Sergej and Schlemon, Maron and Herr, Dennis-Florian and Fuerlinger, Karl and Schulz, Martin and Weidendorfer, Josef, BEAST Lab: A Practical Course on Experimental Evaluation of Diverse Modern HPC Architectures and Accelerators, Journal of Computational Science,2024. ↩
-
Slurm Workload Manager - Documentation, (Accessed on 06/13/2024), Link. ↩
-
Patki, Tapasya and Ahn, Dong and Milroy, Daniel and Yeom, Jae-Seung and Garlick, Jim and Grondona, Mark and Herbein, Stephen and Scogland, Thomas, Fluxion: A Scalable Graph-Based Resource Model for HPC Scheduling Challenges, Association for Computing Machinery,2023 DOI. ↩